By Aniruddha Amrite, ClinPharm Dev Solutions LLC
Executive summary (for busy leaders)
Large language models (LLMs) are already useful across the drug development continuum—if we anchor them to trusted sources and keep humans in the loop. Practical wins today include faster literature synthesis and hypothesis triage, eligibility criteria parsing and patient–trial matching at scale, drafting high-volume documents (protocol sections, safety narratives) with SME review, and decision support when coupled to retrieval-augmented generation (RAG) and internal knowledge bases. Benchmarks in medicine such as Med-PaLM 2 show strong exam-style performance, but hallucinations and reproducibility remain real risks—especially in regulated contexts. A sound adoption plan combines domain-tuned models, RAG, audit logs, and pharmacology leadership to ensure scientific and operational value.
1) Why this matters now
Two converging realities make LLMs relevant to biopharma teams of all sizes:
- The information explosion: biomedical publications, guidelines, internal reports, and meeting minutes vastly outpace human reading capacity.
- Transformer-based models excel at compressing, organizing, and rewriting text at scale—freeing scientists to spend time on decisions rather than document creation.
But drug development is not a generic text task. Precision matters—especially for clinical pharmacology, modeling and simulation (M&S), trial design, and pharmacovigilance. The goal is not to “automate science”; it’s to build a human-guided system where LLMs accelerate evidence gathering, reasoning scaffolding, and communication—with traceability.
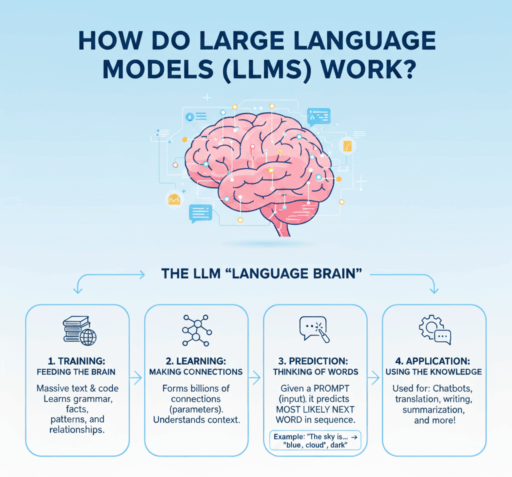
2) A scientist’s primer: how LLMs actually work (without the math)
Modern LLMs are built on the Transformer architecture. During pretraining, they read massive amounts of text and learn to predict the next token (a sub-word unit) given the preceding context. This objective—next-token prediction—teaches the model statistical regularities of language, terminology, and latent relationships (for example, “EGFR inhibitors” with “rash”, or “QTcF” with “concentration–response”).
After pretraining, models are post-trained to be more useful and safer via techniques like supervised fine-tuning and reinforcement learning from human feedback (RLHF). In biomedicine, you also see domain-tuned variants such as BioGPT or Med-PaLM 2 trained or adapted on PubMed and clinical text to improve biomedical reasoning and terminology fidelity.
Key takeaways for scientists:
- LLMs generate text; they do not look up facts unless connected to external knowledge.
- They summarize and transform style or format exceptionally well.
- They can appear to reason; in practice they rely on statistical patterns—hence the need for grounding and verification in regulated work.
3) What “hallucinations” are—and why they matter in drug development
Hallucinations are plausible-sounding but incorrect statements, fabricated citations, or unsupported claims. Common drivers include missing or outdated knowledge (no access to the newest paper or private data), ambiguous prompts, and over-generalization beyond available evidence.
In clinical and regulatory settings, hallucinations can contaminate eligibility criteria, dose rationale write-ups, adverse event narratives, or pharmacology summaries—eroding credibility and, in worst cases, misdirecting decisions.

4) Where LLMs are already creating value
4.1 Literature mapping, hypothesis triage, and mechanism synthesis
LLMs accelerate “what do we already know?”: extracting disease–target relationships, mapping pathways, and summarizing conflicting findings. Domain models such as BioGPT improved performance on PubMed-style Q&A and biomedical entity tasks. Newer reviews catalog broader clinical uses—from target identification to trial analytics.
4.2 Protocol sections and document drafting (with SME sign-off)
High-volume sections—background and rationale, schedule of activities tables, eligibility summaries, and some IND, IMPD, or CSR sections—are ripe for LLM-assisted drafting. You gain speed and consistency while SMEs retain ownership of accuracy. Research-grade models such as Med-PaLM 2 show strong medical Q&A performance; narrative outputs still require grounding and expert review, but they provide excellent scaffolds.
4.3 Trial feasibility and patient–trial matching
Parsing eligibility criteria and matching patients from electronic health records is labor-intensive. LLM-enabled pipelines can improve scale and consistency for matching, with real-world evaluations ongoing. A practical pilot is to encode criteria with an LLM, add rule-based checks for hard exclusions, and run site-level pre-screens on de-identified EHR cohorts—measuring precision and recall against human review before expanding.
4.4 Pharmacovigilance and safety narratives
LLMs and NLP can extract adverse event signals from unstructured text and accelerate patient safety narrative drafting. De-risked deployment follows a risk-based oversight model, uses high-quality training and validation data, and enforces explicit human review points. Generate first-pass narratives with citations to source documents, require safety physician approval, and log differences between model output and final submission.
4.5 Decision support when coupled to quantitative models
LLMs are not replacements for PopPK, PBPK, or QSP, but they translate and contextualize quantitative outputs for diverse audiences and justify parameters with citations. Forward-looking groups are building internal copilots that read model outputs or tables and generate reviewer-ready explanations—for example, ingesting exposure–response plots and drafting a concise dose-selection rationale.
5) Case studies and recent signals from the literature
- Med-PaLM 2: strong performance on medical Q&A benchmarks such as MedQA, MedMCQA, and PubMedQA, illustrating the ceiling for text-based reasoning when properly grounded.
- End-to-end patient–trial matching: multiple 2024–2025 studies show criteria parsing and EHR matching with human oversight and auditing.
- RAG in biomedicine: healthcare analyses show RAG improves correctness and reduces hallucinations versus base LLMs, particularly with curated corpora and section-aware retrieval.
- Domain-tuned models: BioGPT and newer medical LLMs show better biomedical priors and terminology handling than general-purpose models.
6) A practical framework for adoption in translational and clinical teams
6.1 Choose the right model and deployment pattern
- General-purpose LLM plus RAG as a default, paired with curated corpora such as PubMed and internal documents.
- Domain-tuned LLMs for terminology fidelity—still with RAG.
- Access model: API versus on-premises. For proprietary content, consider private VPC or on-prem inference.
6.2 Build a trustworthy knowledge stack
- Automated document pipelines to ingest PDFs, extract tables and figures, deduplicate, and tag with metadata (trial ID, indication, modality, biomarker).
- RAG tuning: appropriate chunk sizes, section-aware retrieval, and table extraction for PK or PD content.
- Enforce inline citations (PMIDs or DOIs) for every claim used downstream.
6.3 Governance, validation, and human oversight
- Risk-based approach: map use cases to risk levels and define required human checks and sign-offs.
- Validation datasets: internal gold standards such as eligibility sets or safety narratives for periodic re-testing.
- Auditability: log prompts, retrieved documents, model versions, and editor approvals, and lock artifacts for inspections.
7) Ways to reduce hallucinations (concrete controls that work)
- RAG with curated sources: constrain retrieval to PubMed, internal SOPs, prior submissions, and validated datasets rather than the open web. Require a minimum number of supporting citations per claim.
- Precise prompt contracts: specify scope, ontology (for example, MedDRA), citation style, and mandatory fields such as dose units, population, and endpoint. Include “don’t know → say so.”
- Counter-prompting: after drafting, instruct the model to critique itself, listing uncertainties, assumptions, and weak links, and flag where evidence is thin.
- Guardrail checkers: use a secondary validator to confirm that cited sources exist and support the claims. Reject or flag when confidence is low.
- Domain-tuned models: prefer biomedical LLMs for clinical or scientific tasks to reduce terminology and entity errors.
- Human-in-the-loop: require SME review for all regulated outputs and treat AI drafts as scaffolds, not final text.
- Versioning and audit logs: store prompts, retrieved passages, model versions, and reviewer approvals; make outputs traceable for audits.
In practice, preventing or reducing hallucinations in LLM workflows requires attention to four broad pillars that complement one another. First, improving data quality by training on verified, diverse, and bias-filtered datasets reduces misinformation propagation. Second, advanced training techniques such as Reinforcement Learning with Human Feedback (RLHF) align the model’s outputs with factual and human-relevant values. Third, context and verification strengthen reliability by ensuring prompts include sufficient background and enabling AI systems to reference external, real-time databases for fact-checking. Finally, building uncertainty and feedback loops into workflows allows models to indicate when they do not know an answer and lets user feedback guide continuous improvement. Simply put, better data, smarter training, and systematic fact-checking are essential for dependable AI performance in scientific applications.

8) Cost–benefit: where the ROI is real
- Time saved on first drafts such as protocol sections, background, and eligibility summaries scales with portfolio size.
- Higher throughput of literature synthesis and competitive intelligence.
- Better cross-functional communication: LLM-generated lay summaries and executive briefs increase engagement with modeling outcomes.
- Fewer lost insights: RAG and internal repositories surface prior analyses and decisions when staff turns over.
9) What to pilot in the next 30–60 days (playbook)
- Clinical pharmacology dossier copilot: build a corpus of exposure–response reports, PopPK summaries, CSRs, and key literature. Output a one-page dose-selection rationale with figures and references. Measure SME edit time and unsupported claims.
- Eligibility extraction and cohort pre-screen: start with one oncology trial, encode criteria, run de-identified EHR pre-screens, compare to human screeners, and measure precision and recall and time saved.
- PV safety narratives: generate drafts from structured fields and case notes with citations, require physician review, and track edit distance and cycle time.
- Literature triage copilot: weekly digest with PMIDs or DOIs and evidence grading; track useful leads per week.
10) Frequently asked questions
Q: Can an LLM help pick first-in-human (FIH) dose?
A: It can summarize supporting evidence and prior analogs and draft a dose rationale, but numerical decisions stay with M&S. Use it to speed evidence assembly and clarity—not to replace PopPK, PBPK, or QSP.
Q: Are we allowed to use LLMs on regulated content?
A: Yes, with controls such as private deployment, curated corpora, citations, human review, and audit logs. For pharmacovigilance, follow a risk-based approach with human oversight.
Q: How do we keep it current?
A: Nightly ingestion of PubMed results and internal documents, RAG index refresh, and periodic evaluation on internal gold-standard tasks.
References
- Vaswani A, Shazeer N, Parmar N, et al. Attention Is All You Need. arXiv:1706.03762 (2017).
- Lewis P, Perez E, Piktus A, et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP. NeurIPS (2020).
- Luo R, Sun L, Xia Y, et al. BioGPT: Generative Pre-trained Transformer for Biomedical Text Generation and Mining. Briefings in Bioinformatics (2022).
- Singhal K, Tu T, Gottweis J, et al. Toward expert-level medical question answering with large language models (Med-PaLM 2). Nature Medicine (2025).
- Yang R, Zhou J, He Z, et al. Retrieval-augmented generation in healthcare: equity, reliability and personalization. npj Digital Medicine (2025).
- Jin Q, Yang Z, Wei C-H, et al. Matching patients to clinical trials with large language models. Nature Communications (2024).
- Rajendran A, Selvaraj S, Kazi A, et al. PRISM: Patient Records Interpretation for Semantic clinical-trial Matching. npj Digital Medicine (2024).
- CIOMS Working Group XIV. Artificial Intelligence in Pharmacovigilance (Draft for Public Consultation). (2025).
- Singhal K, Azizi S, Tu T, et al. Large language models encode clinical knowledge (Med-PaLM). Nature (2023).
- Abramson J, Wallner B, Jumper J, et al. Accurate structure prediction of biomolecular interactions with AlphaFold 3. Nature (2024).
Abbreviations
AE: Adverse Event
CIOMS: Council for International Organizations of Medical Sciences
CSR: Clinical Study Report
CTA: Clinical Trial Application
EHR: Electronic Health Record
ER or E–R: Exposure–Response
FIH: First-in-Human
HITL: Human-in-the-Loop
IMPD: Investigational Medicinal Product Dossier
IND: Investigational New Drug
LLM: Large Language Model
MedDRA: Medical Dictionary for Regulatory Activities
M&S: Modeling and Simulation
PBPK: Physiologically Based Pharmacokinetics
PK: Pharmacokinetics
PD: Pharmacodynamics
PopPK: Population Pharmacokinetics
PV: Pharmacovigilance
QSP: Quantitative Systems Pharmacology
RAG: Retrieval-Augmented Generation
RLHF: Reinforcement Learning from Human Feedback
SME: Subject Matter Expert
SOP: Standard Operating Procedure